For two years, the debate about AI in medicine has been about answers. Can the model get the diagnosis right? Can it pass the board exam? MIRA changes the question. It doesn’t answer — it acts.
A team led by Jakob Nikolas Kather, with Dyke Ferber doing the heavy lifting, just published MIRA in Nature. The agent runs a full emergency-department case end to end: it takes the history, orders and interprets labs and imaging, prescribes medications, schedules procedures, and decides whether to admit. On 574 real cases it reached an average diagnostic accuracy of 88.9% — and on the matched head-to-head it beat board-certified physicians, 87.8% to 78.1%. Jorge Reis-Filho, who leads AI for Science Innovation at AstraZeneca, called it “a remarkable step for agentic AI in clinical practice.”
The agent itself will get the headlines. But the shift that matters is quieter: the line between AI that advises and AI that acts just got crossed — in a benchmarked, standards-compliant way. That is exactly the line my last few articles, and ESMO’s governance work, have been circling.
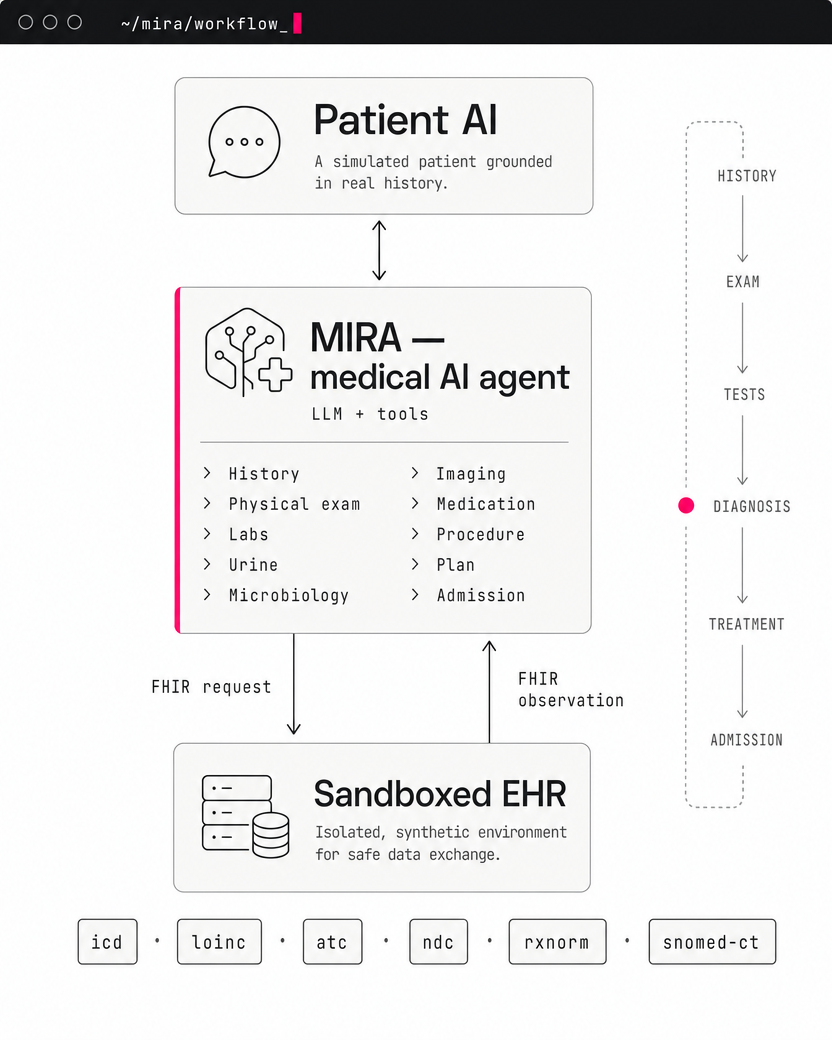
How MIRA runs a case end to end — a patient agent in dialogue with the agent, which calls clinical tools, sends FHIR requests to a sandboxed EHR, and reads back the results, all the way from history to admission.
Where MIRA Sits in ESMO’s Governance Map
If you followed my piece on ESMO’s AI governance architecture, you know it has three frameworks. ELCAP governs large language models in clinical practice. EBAI governs AI-based biomarkers. And EVAGENT — still in development — is the one reserved for autonomous agents that don’t just answer but act.
MIRA is not an ELCAP tool and not an EBAI tool. ELCAP’s HCP-facing tier insists that physicians keep full accountability — no delegating decisions to the model. MIRA makes and executes those decisions inside a sandboxed electronic health record. It is precisely the “distinct safety, regulatory and ethical challenges” that ESMO says EVAGENT exists to cover.
Here’s the part worth sitting with. Usually the gap between research and governance means the rules arrive years late. Not here. Jakob Kather — MIRA’s senior author — also helps lead ESMO’s AI classification work and the design of EVAGENT itself. So MIRA isn’t merely a system that will need EVAGENT; it’s a working prototype of what EVAGENT is likely to formalize. Its evaluation is not a single ”% correct.” It benchmarks the whole pathway against physicians: faithfulness of history-taking, test selection versus over-ordering, guideline concordance, medication safety across six distinct risk domains, admission recall, adversarial robustness, and behavior under patient-bias perturbations. That is Jorge’s central point — benchmark the process, not the endpoint. The same hands that built this agent are now helping write the standard it should be judged by.
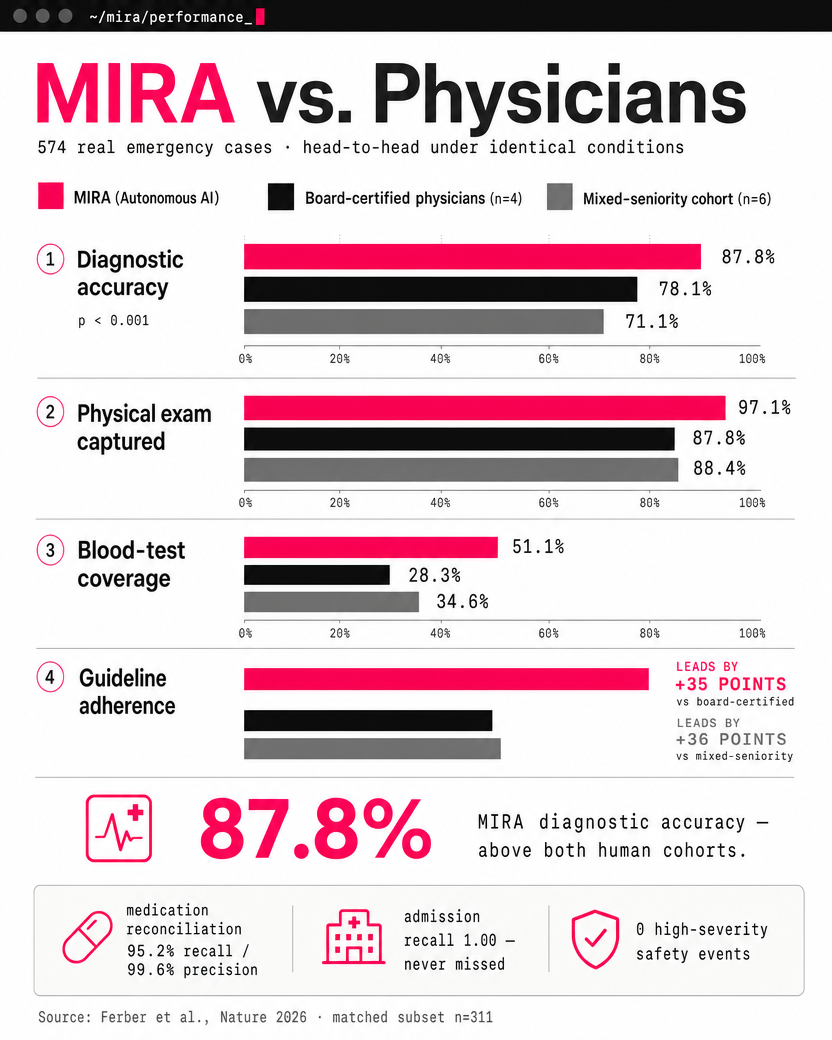
MIRA versus two physician cohorts on the matched head-to-head (n=311 of 574 cases), under identical conditions. It leads on diagnostic accuracy, examination thoroughness, test coverage and guideline adherence — while never missing a required admission. Source: Ferber et al., Nature 2026.
What Happens When You Swap in a 2026 Model
One detail gets lost in the celebration: MIRA runs on GPT-4o, with an older reasoning model for planning. By today’s standards, that is already a generation behind. So the obvious question is what a current frontier model — a GPT-5.5, or Claude Opus 4.8 — does to these numbers.
Accuracy and guideline adherence will climb, and tool orchestration will get more reliable. But the sharper consequence is the one I argued in the deletion article: a better model lets the scaffolding shrink. The heavy planning step and the prompt machinery that propped up GPT-4o may become dead weight on a model that plans natively. The harness that was load-bearing last year becomes drag this year.
Two caveats Medical Affairs should hold onto. First, contamination: MIMIC-IV is a public dataset, so tomorrow’s models may well have seen it — treat any single-dataset result as a likely upper bound, not a deployment guarantee. Second, ceiling effects: on straightforward presentations like appendicitis MIRA is already near 99%, so a bigger model’s marginal value shows up in the hard cases and in safety, not in the headline accuracy.
The takeaway is uncomfortable and clarifying at once. The model is the fastest-improving and least defensible part of the system. The durable bottleneck is the harness, the integration, and the evaluation — which happens to be the part that people who own process are best placed to build.
Eleven Tools, or an Army of Subagents?
When you see MIRA juggling 11 tools and more than 85,000 coded options, a tempting instinct kicks in: wouldn’t this be cleaner as a swarm of specialists? One subagent that only orders bloods, another that only interprets them, a third for imaging?
I’d resist that, and the reason is the Vercel lesson from my last article. When Vercel’s engineering team deleted roughly 80% of their agent’s tools and let one capable model reason directly over the data, the agent got 3.5× faster, its success rate rose from 80% to 100%, and it got cheaper to run.
We were constraining reasoning because we didn’t trust the model to reason.
Splitting “order the bloods” from “interpret the bloods” is exactly that kind of distrust. It manufactures handoffs, drift, and audit surface for no clinical gain — a capable model interprets the labs it just ordered.
But MIRA’s tools are not Vercel’s tools, and the distinction is everything. MIRA’s 11 tools wrap tens of thousands of token-masked options that enforce FHIR compliance — they exist so the agent cannot invent a non-existent drug code or an invalid order, not to walk it through its reasoning. That scaffolding is load-bearing for safety and interoperability. You keep it.
So where do subagents actually earn their place? For genuinely separable risk concerns, not for task-splitting. MIRA’s own authors propose a cost-steward subagent — inspired by Microsoft’s MAI-DxO — that tracks the cumulative cost of tests and flags expensive imaging in real time. An independent safety checker is another candidate. The rule of thumb: add a subagent when it owns a distinct risk you’d want to audit on its own, never to break one clinician’s reasoning into assembly-line steps.
From Sandbox to Bedside
It’s worth being honest about how far this is from a real emergency department. MIRA was tested against a simulated patient — an agent grounded in the tidy history written into a discharge summary. Real patients don’t talk like discharge summaries. They ramble, contradict themselves, forget the name of the drug they take every morning, switch languages, and leave out the symptom that mattered most. Before any system like this earns autonomy, it has to be evaluated on messy, real-world transcripts — not a clean chat interface — and that gap is wide.
Which points to the realistic next step, and it isn’t autonomy. It’s a copilot. Picture the physician leading the conversation while ambient transcription captures it in real time. The agent listens, suggests the follow-up question the clinician might not have asked, and quietly begins assembling the workup in the background — pre-drafting the lab panel, flagging a drug interaction, lining up the imaging request for a human to approve. The physician keeps the relationship and the judgment; the agent contributes thoroughness and speed. That is the synergy worth building toward: human and machine each doing what they are best at, rather than one standing in for the other.
What to Do With This
- Map your agents to ESMO’s tiers — and watch for the drift. The moment a tool stops suggesting and starts executing, it has left ELCAP for EVAGENT territory, and your evidence bar changes with it.
- Benchmark the pathway, not the endpoint. Borrow MIRA’s shape: faithfulness, resource use, guideline concordance, safety, robustness — not just whether the final answer was right.
- Treat every model upgrade as a review trigger. A stronger model may let you delete scaffolding, or may have outgrown a guardrail that is now a cage. Re-check, and put the reasoning on the record.
- Right-size the structure. Default to the fewest tools and subagents that still run reliably and stay auditable. Add a subagent for a distinct risk, not a distinct task.
- Pilot as a copilot, not an autopilot. The first real deployments should keep the physician in the conversation and the agent in the background — suggesting questions and pre-assembling the workup for human approval, not acting alone.
The Bigger Picture
MIRA is not a product you’ll deploy next quarter. It’s a proof — that a general model, wrapped in the right harness and held to a pathway-level benchmark, can carry a clinical encounter at physician level. And the frontier, as Jorge put it and as Google and DeepMind’s back-to-back Nature paper independently confirmed, is no longer the model. It’s the framing, the scaffolding, and the evaluation.
That is the most pharma-shaped sentence I’ve written all year. Process discipline, risk-based review, validated evidence, the willingness to retire what no longer earns its keep — the habits our industry is accused of being slow about are exactly what acting agents will need in order to be trusted. The teams that internalize that now won’t be catching up to EVAGENT. They’ll be the ones writing what goes into it.
This article was co-authored with Anthropic’s Claude Opus 4.8 model. The ideas, domain expertise, and editorial direction are mine — the AI helped structure, draft, and refine the text.
